
Zero-Downtime AWS Autoscaling Groups with Terraform
Hosting your own web application server? Then you may have heard that autoscaling groups are pretty great. But what happens when you need to update the AMI or replace the underlying web application server? Tearing down and re-provisioning the instances in your autoscaling group will result in a service outage. So, what is a (Terraform) developer to do?
![]()
Credit: Amazon Web Services
What are Autoscaling Groups?
An Auto Scaling group contains a collection of Amazon EC2 instances that are treated as a logical grouping for the purposes of automatic scaling and management. An Auto Scaling group also enables you to use Amazon EC2 Auto Scaling features such as health check replacements and scaling policies. Both maintaining the number of instances in an Auto Scaling group and automatic scaling are the core functionality of the Amazon EC2 Auto Scaling service.
Put simply, autoscaling groups allow you to manage a group of EC2 instances like cattle. The group will automatically scale up by adding additional instances or scale down by removing instances based on certain targets or conditions. When an instance is unavailable or otherwise not healthy, it will be discarded and a new instance will take its place. If that sounds pretty cool, it is. Oh, and another cool thing about autoscaling groups is that they can distribute instances across subnets and even availability zones to improve the availability of the group as a whole.
**Note: The term “cattle” used above was a reference to Randy Bias’s 2011 coined phrase, “cattle, not pets.” The phrase refers to managing resources in the cloud as a function of the service they collectively provide instead of based on individual bespoke “pet” servers.
The Scenario
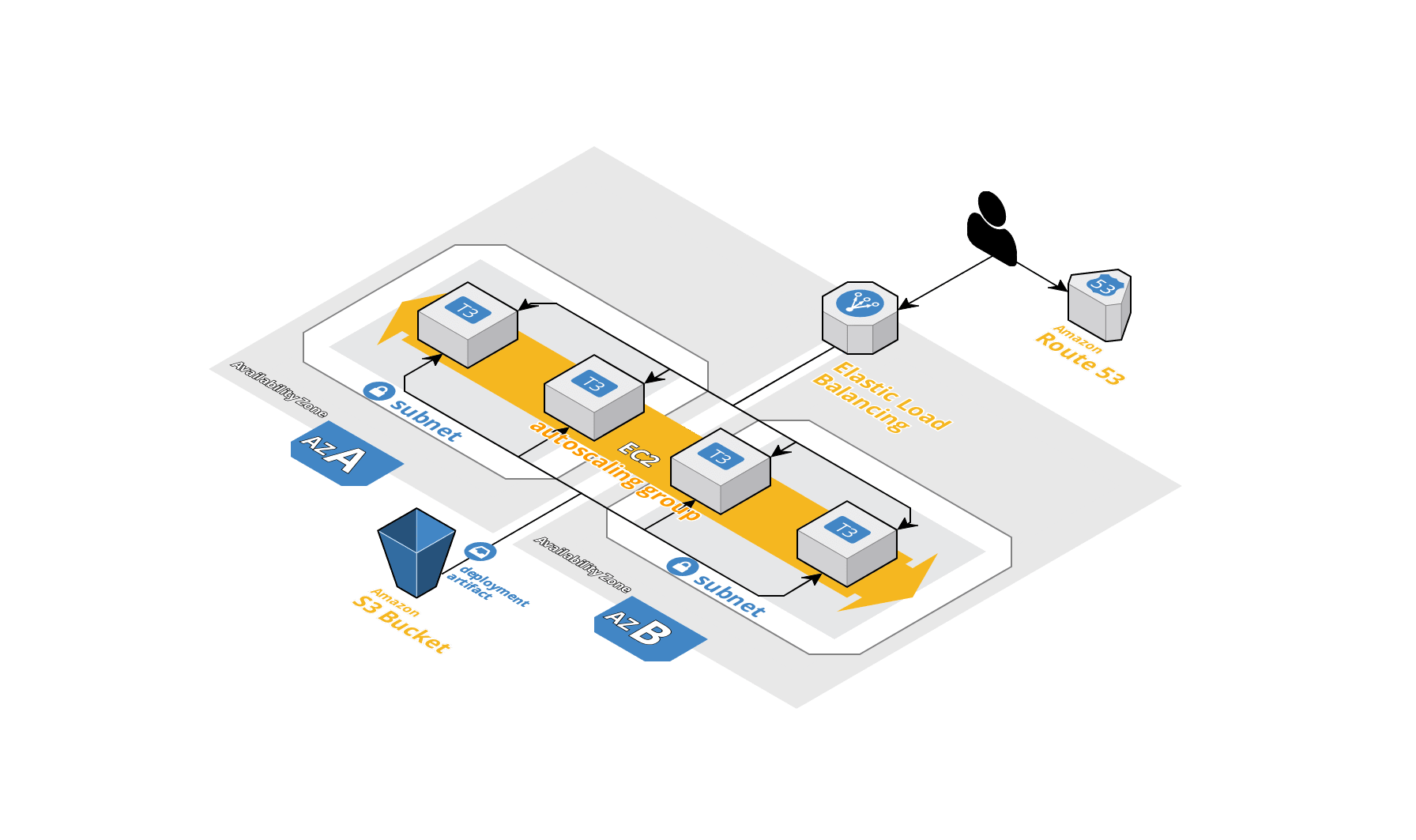
Autoscaled Web Application Servers; Created using Cloudcraft
Let’s say that we want to deploy a web application server (e.g. Spring Boot, Express or Flask). Following the description of autoscaling groups above, it makes sense that we would want an autoscaling group instead of one or more independently managed EC2 instances. But autoscaling groups don’t come without their own challenges. When should the group scale up? When should the group scale down after it’s scaled up? What is the ideal size for typical load? How can we ensure continuous service during a deployment?
Discussing how to answer all of those questions is beyond the scope of this post. And indeed, even attempting to answer all of those questions would make this a very lengthy post. That’s why we are focusing on just one of those questions.
How can we ensure continuous service during a deployment?
But more than that, we are focusing on how to answer that question using Terraform.
OK, OK, back to the scenario description. We have a web application server as described above in an autoscaling group that’s distributed across private subnets in different availability zones in our own VPC. We also want a load balancer in front of the autoscaling group distributed across public subnets in those same availability zones. Additionally, we want to be able to execute deployments simply by issuing a terraform apply command, which should redploy the web application server without any downtime (aka zero-downtime).
In a Nutshell
Once provisioned, the load balancer will receive HTTP requests from the Internet - a public DNS endpoint is attached to the load balancer along with a certificate associated with the domain (this allows us to use a public URI, like https://www.mydomain.com for the web application). When the load balancer receives the request, it will route the request to one of the application servers in the autoscaling group, which will process the request and return a response. The load balancer will have access to all the instances in the autoscaling group. However, only the load balancer will be available on the public Internet.
Our (AWS) Options
1. Elastic Beanstalk
Elastic Beanstalk is an all-in one PaaS (Platform as a Service) application hosting solution that does come with autoscaling built-in. And it’s pretty great for quickly deploying a web application, especially a public facing web-app. But once you start doing things like putting your infrastructure in your own VPC, specifying private subnets for your autoscaling group instances and public subnets for your load balancer and working with VPC endpoints, suddenly Elastic Beanstalk goes from a simple opinionated solution to a more complicated custom configuration mess.
2. ASG + Load Balancer
We chose to define a launch configuration for our autoscaling group and then attach a load balancer to our autoscaling group. We found this gave us a lot of granular control and it wasn’t really any more effort than configuring Elastic Beanstalk. However, Elastic Beanstalk does provide a relatively easy way to deploy/update our application, which we were able to more or less replicate.
The Solution
The Autoscaling Group
Up until recently, Terraform didn’t support autoscaling group update policies. And now, it only supports rolling updates. We haven’t tested that out with Terraform yet. So, our solution is more along the lines of what Paul Hinze of HashiCorp discussed HERE. The basic idea is that we used Terraform’s create_before_destroy lifecycle events on the launch configuration and on the autoscaling group resources.
When the launch configuration is updated, either by changing the AMI or the userdata, the launch configuration is destroyed and recreated, which also triggers the autoscaling group to be destroyed and recreated. The create_before_destroy lifecycle events cause the new autoscaling group to be brought up and attached to the load balancer while the existing autoscaling group is still attached to the load balancer. Once the new autoscaling group is available, the previous/existing autoscaling group is destroyed. The net result is that there is a brief period of time when instances from both autoscaling groups are attached to the load balancer. But at no point is there a disruption in service.
resource "aws_launch_configuration" "this" {
instance_type = var.instance_type
image_id = var.ami
root_block_device {
delete_on_termination = true
volume_size = var.volume_size
}
key_name = length(var.keypair) > 0 ? var.keypair : null
security_groups = [aws_security_group.instance.id]
user_data = base64encode(templatefile("${path.module}/.scripts/userdata.sh", {
userdata = var.userdata
}))
iam_instance_profile = aws_iam_instance_profile.this.name
lifecycle {
create_before_destroy = true
}
}
resource "aws_autoscaling_group" "this" {
name = "${local.app_name}-${aws_launch_configuration.this.name}"
desired_capacity = length(var.desired_capacity) > 0 ? var.desired_capacity : var.min_size
min_size = var.min_size
max_size = var.max_size
vpc_zone_identifier = data.aws_subnet_ids.public.ids
launch_configuration = aws_launch_configuration.this.name
load_balancers = [var.lb.id]
min_elb_capacity = length(var.desired_capacity) > 0 ? var.desired_capacity : var.min_size
lifecycle {
create_before_destroy = true
}
}
Take note of a few things: (1) no name is specified for the launch configuration (2) the launch configuration’s name is part of the autoscaling group’s name (3) some of the userdata is externally supplied. The launch configuration’s name is intentionally left blank so that a name will be auto-generated, thereby avoiding collisions. The autoscaling group’s name includes the launch configuration’s name, which forces the autoscaling group to be replaced. Finally, some userdata can be supplied because we made a concious decision to not use baked images (easier to manage and easier to share associated code, like in blog posts :) and we don’t presume how the webapp is hosted or executed (Docker, Spring Boot, Flask, whatever…). So, any tech can be bootstrapped by supplying that in the userdata - we just presume it’s a web app.
Warning: Don’t Make These Mistakes
Terminating the existing autoscaling group prior to bringing up a new autoscaling group or updating the autoscaling group, terminating its instances and waiting for new instances to be re-created will result in a service outage. This is noted because we’ve seen organizations make these mistakes. Don’t let that be you!
Deploying Updates
There are two scenarios which require a deployment: (1) the AMI changed and (2) the application changed. When the AMI is changed, the launch configuration changes, which as stated above will trigger a new launch configuration and a new autoscaling group. But what about triggering a deployment when the application is changed? That’s where userdata comes in.
If the userdata is changed from its previous state, that will also trigger a new launch configuration and a new autoscaling group. Now, you’re probably thiking that userdata is supposed to be relatively terse code that bootstraps the EC2 instances. Wouldn’t that remain constant? And yes, that’s true. But if we say, echo a version number based on an input variable then that would have the effect of changing the userdata without changing any meaningful functionality. Yea, it’s a hack. But not a damaging one - just a mechanism to provide us Beanstalk-esque deployment functionality with a Terraform autoscaling group + load balancer (zero-downtime) deployment configuration.
Oh and speaking of Elastic Beanstalk… when a deployment is executed, an artifact is uploaded to S3, where it is extracted by the instances in its autoscaling group and then the extracted contents are used to launch the (web) application. The solution described above allows us to do the same thing. The trigger for re-deployments is changing a Terraform input variable value.
Wrapping It Up
There are a ton of details about creating an autoscaling group + load balancer zero-downtime deployment configuration with Terraform that were omitted for the sake of brevity. For example, wiring up security groups, configuring the load balancer, and setting up S3. Indeed, all of that should be included in a complete working example.
So, we decided to provide such an example HERE.
In the complete working example linked above, we assume that private and public subnets already exist in a VPC and they are appropriately tagged as such. We further assume that Route53 has a public zone configured and that a *.{domain name} certificate for that zone is registered in ACM. The example itself is composed of 2 Terraform submodules and a root module: a submodule for the autoscaling group configuration, a submodule for the load balancer configuration (we used a Classic Load Balancer in this case for simplicity) and root module to serve as an entry point and to tie everything together.
The web application deployed is expected to be defined using a Dockerfile, which should expose port 8080 for the reverse proxy configured using an Apache Web Server (80 -> 8080).
Omissions
One omission you may have noticed was the functionality to match the number of available instances in the previous/existing autoscaling group with those in the new autoscaling group. Autoscaling group policies were also intentionally omitted. Those topics, however, will be addressed in a future post.
Credits
We would love to say that we came up with this all on our own. But that wouldn’t be entirely truthful. We need to give credit where credit is due. Below is our list of credits.
- Paul Hinze @HashiCorp for posting about this approach
- Gruntwork for implementing the solution, doing a little writeup, and for linking to Paul Hinze’s post
- Robert Hutto for demonstrating the implementation
Of course, all work posted here is original - none of it was copied. But that’s not to say that we didn’t have some help or some inspiration from the people (and the organization) listed directly above.



